
Il s'agit de l'outil appelé Trustworthy Language Model (TLM) , qui cherche à offrir une « couche de confiance » grâce à un système de notation qui évalue la fiabilité des réponses fournies par ces modèles de langage génératifs (LLM).
Cette évolution vise également à favoriser l’expansion de ces systèmes dans différents secteurs, à l’heure où, selon une récente étude de Gartner, qui révèle que même si 55 % des organisations expérimentent l’IA générative, seulement 10 % l’ont effectivement mise en œuvre. dans leurs processus de production .
Comment fonctionne le modèle linguistique digne de confiance
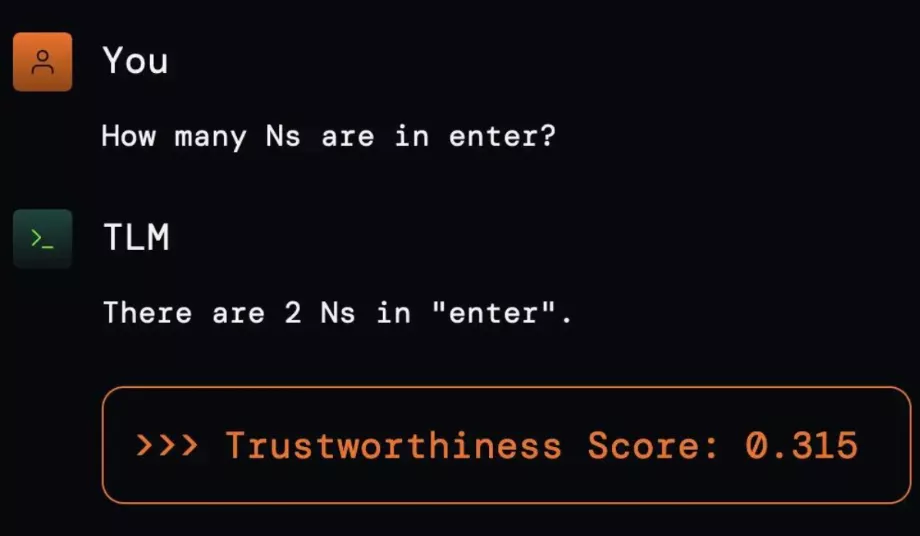
TLM fonctionne en attribuant un « score de fiabilité » à chaque réponse générée par le modèle, permettant d'identifier et de filtrer les réponses peu fiables. De plus, un système a été mis en œuvre pour générer plusieurs réponses en interne, sélectionnant celle ayant le score de confiance le plus élevé à présenter à l'utilisateur.
Cette méthodologie réduit non seulement les cas de réponses incorrectes, mais s'est également avérée plus performante que les modèles préexistants, notamment le GPT-4 d'OpenAI .
De même, il offre une intégration facile avec les systèmes existants , fonctionnant comme un remplacement direct ou comme un complément qui ajoute une couche de fiabilité sur les résultats générés, à la fois par les LLM et par les données produites par les humains.
C'est pourquoi l'objectif de TLM est de devenir une solution au problème des « hallucinations » des chatbots, qui se produisent selon les estimations dans au moins 3 % des cas , un véritable problème pour les professionnels recherchant le plus haut degré de précision.
Comment les « hallucinations » peuvent causer de graves problèmes

Parmi les exemples d'erreurs coûteuses figurent le chatbot d'Air Canada, qui a entraîné des politiques de remboursement inexistantes , et un cabinet d'avocats pénalisé pour avoir inclus des devis fabriqués de toutes pièces dans un document juridique, en raison de l'utilisation de ces modèles linguistiques.
Une autre preuve de ce problème a été rencontrée par un avocat qui, en utilisant ChatGPT pour préparer des documents juridiques, a découvert des références et des citations judiciaires incorrectes dans leur contenu . De plus, il a été signalé que ChatGPT peut commettre des erreurs dans des tâches simples, telles que calculer le nombre de fois qu'une lettre apparaît dans un mot spécifique.

Ce problème met en évidence l'importance d'établir des mécanismes de vérification des informations générées par l'IA telles que TLM, en particulier lorsque l'utilisation de grands modèles de langage (LLM) tels que GPT-3.5, GPT-4 et de modèles commerciaux personnalisés se développe dans le domaine commercial .
Tandis que la disponibilité de TLM via une interface de programmation d'application (API) et dans des versions gratuites et payantes avec des fonctionnalités supplémentaires, élargit encore son accessibilité et son utilité pratique.
Pourquoi l’intelligence artificielle commet des « hallucinations »
Dans ce contexte, le terme « hallucination » est une métaphore pour les situations dans lesquelles l'IA crée des résultats sans rapport avec la réalité ou incorrects , et se produisent lorsque les modèles, en particulier ceux basés sur l'apprentissage profond, interprètent de manière incorrecte les données d'entrée ou les modèles contenus dans les données. sur lequel ils ont été formés.
Cela peut se produire pour un certain nombre de raisons, telles que des biais dans les ensembles de données d'entraînement , un surajustement (lorsqu'un modèle apprend si bien les données d'entraînement qu'il ne parvient pas à les généraliser à de nouvelles données) ou une mauvaise interprétation de modèles complexes ou ambigus dans les données. données.

Ils peuvent également résulter d’une extrapolation inappropriée. Lorsqu'un modèle d'IA est confronté à des situations ou à des données très différentes de celles sur lesquelles il a été formé , il peut générer des réponses basées sur des modèles appris qui ne s'appliquent pas correctement à la nouvelle situation.
De plus, le langage humain est complexe et ambigu, ce qui peut amener le chatbot à mal interpréter le contexte ou le sens des questions ou des affirmations, notamment dans des languesaux sens multiples ou très riches en expressions idiomatiques.